

About This Project
I try to read books on nature, nature history and popular science as much as I can. Then I wondered is there a gender gap in the amount of published books in these fields. I became curious about the percentage of women, trans and non-binary nature history writers.
I found some good articles about gender gap in publishing. In her visual article in The Pudding, Rosie Cima (2017) analyses the the gender balance of The New York Times best seller list. This research on gender gap in academia (Holman, Stuart-Fox and Hauser, 2018) and its interactive webpage is also worth looking. Of course, in all these research gender is binary.
Main Questions
- Where to access nature history book authors?
- Where to access author gender data?
- Is there a gender gap in the published nature history books?
How to find authors’ gender identity?
There are some services that libraries can use like Novelist (which is a division of EBSCO now) that provides detailed information about books and their authors. In 2020 Novelist broadened their database to include trans and non-binary to their database (Reno, 2020). This service is available in Novelist Plus but my university is not subscribed to that. So is there another database for author gender identities? Enters VIAF.
What is VIAF? You can read more about VIAF here. It is a database that combines information from multiple authorities including libraries.
Why I use it? There are personal pages for many authors in VIAF. Each page includes information about the authors’ publication and personal data, including their gender. Check Urusla K. Le Guin’s page here for example.
Downsides?
- Not all authors have gender data in the database
- Binary gender system
The gender category for authors is binary. Check for instance one of my favorite non-binary authors page, Annalee Newitz. Annalee is categorised as “Female”. So here is a shout out to VIAF:
Please update your database to include more than two genders!
(Not that anyone will here me from this tiny blog buuut….🤨. Yeap, my rant is finished now. Moving on.)
Where to download? I downloaded their date (here). The unzipped “txt.gz” file is 9,37 GB.
How to decrease the file size to make quicker analysis? When I observed the VIAF dataset, I realised that a single author had dosens of rows and I only needed a single row containing the authors’ VIAF webpage link (which is accompanied by a wikipedia link). So lets only keep the rows that has a wikipedia link.
Obviously a problematic approach as there might be many authors in my dataset without a wiki page. But nevertheless this helped me to decreased the file size from ~ 9 GB to ~ 235 MB.
What if VIAF doesn’t have the author’s gender?
Then I can use Natural Language Toolkit to predict the authors’ gender from their first name. NTLK helps us with statistical natural language processing. The prediction is, yes you guessed it, of course binary.
Personal Note: I would like to understand how the text training and prediction is happening in Natural Language Toolkit. Read about NLTK for example from here.
Finding the Nature History Writers
There are many book retailer webpages with decent categorisation of millions of books. So creating a book dataset with author names and book titles is relatively easy. I used Book Depository and scraped its pages with python.
They have a category called “Natural History”. Perfect. I fetched all the books under this category. The result was ~ 10,000 books with titles, authors and publishing year. I filtered the result to get the books published in 2021.
There are no gender identity information for authors in Book Depository nor in similar platforms. And this is why I need VIAF dataset.
Code Workflow
- Import Book Depository data
- Import VIAF data
- Cross check and match if an author listed in the Book Depository data exists in VIAF dataset.
- If yes: Go to authors page and get their gender info
- If no: Try to predict the authors’ gender from their first name by using Natural Language Toolkit
- Summarise the findings
Result
- There are 982 books published in 2021 within “Nature History” category.
- I retrieved the author gender of~ 32% of these books from VIAF page.
- For the remaining ~68% of the books/authors I used Natural Language Processing to predict their gender from their first names.
- This method couldn’t define gender of 15% of the authors .
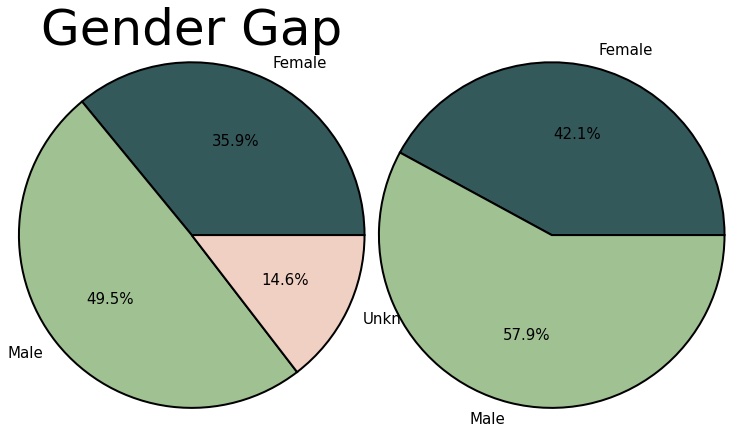
- The results show (excluding the undetermined authors) that 6 out of 10 natural history books that were published during 2021 are written by male authors.
However it’s difficult to fully rely on these results. There are numerous things to improve in this project besides finding a database with broader gender identities. These are:
- Re-consider the use of VIAF database. Just to find gender data for ~30% of the authors the project processing time increases dramatically.
- Improving the Natural Language Toolkit (NTLK) results to increase the binary-gender prediction accuracy.
What I Learned?
- There are very few database that has authors’ gender identity.
- The freely accessible database VIAF has binary gender system.
- Using VIAF and retrieving authors’ gender significantly slowed down the project processing time.
- Moreover, I only managed to retrieve 30% of the nature history authors’ gender data from VIAF.
- For the rest 70% of the authors I had to predict their gender from their first name by using Natural Language Toolkit (NLTK) python library.
- Despite possible lower accuracy it might be worth to only use Natural Language Toolkit and predict authors’ (binary) gender from their first names. In fact, I analysed all the books published in nature history between 1995 and 2020. This method was much more efficient. Read about it here. The code is here.
Code
1
2
3
4
import requests
import pandas as pd
import datetime
from bs4 import BeautifulSoup
Bookdepository Dataset
This dataset is a result of webscraping. I fetched books that were published under natural history category in bookdepository webpage. The result was ~ 10,000 books with titles, authors and publishing year. I filtered this data and retrieved the natural history books for each year between 2015 and 2021. In this project I will check only the books published 2021 = 982 books.
1
2
3
# Import Bookdepository CSV
books = pd.read_csv(".../Bookdepository/NaturalHistory-Bookdepository-2021.csv", dtype=str)
books.head(5)
| Unnamed: 0 | authors | titles | date | year | |
|---|---|---|---|---|---|
| 0 | 17 | Merlin Sheldrake | Entangled Life | 02 Sep 2021 | 2021 |
| 1 | 35 | Jeremy Clarkson | Diddly Squat | 11 Nov 2021 | 2021 |
| 2 | 38 | Lia Leendertz | The Almanac | 02 Sep 2021 | 2021 |
| 3 | 43 | Sosuke Natsukawa | The Cat Who Saved Books | 16 Sep 2021 | 2021 |
| 4 | 62 | James Stewart | Dinosaur Therapy | 24 Aug 2021 | 2021 |
Virtual International Authority File (VIAF) Dataset
This is the dataset downloaded from here. The unzipped file is 9,37 GB.
When I observed the VIAF dataset, I realised that a single author had dosens of rows and I only needed a single row containing the authors’ VIAF webpage link. So lets simplify the csv file by only keeping the rows that has a VIAF link. Decreased the file size from ~ 9 GB to ~ 235 MB.
1
2
3
4
5
# Import VIAF CSV (I changed the way I edited VIAF file. This is the 2nd version)
viaf_db = pd.read_csv(".../Viaf/Viaf-simple.csv", dtype=str)
viaf_db.head(5)
| Unnamed: 0 | viaf | info | Name | |
|---|---|---|---|---|
| 0 | 11 | http://viaf.org/viaf/10001407 | Wikipedia@https://cs.wikipedia.org/wiki/Pavel_... | Pavel Hrach |
| 1 | 70 | http://viaf.org/viaf/100109330 | Wikipedia@https://fr.wikipedia.org/wiki/Emile_... | Emile de Meester de Ravestein |
| 2 | 121 | http://viaf.org/viaf/100144403 | Wikipedia@https://cy.wikipedia.org/wiki/Teresa... | Teresa Magalhães |
| 3 | 246 | http://viaf.org/viaf/100177876 | Wikipedia@https://nl.wikipedia.org/wiki/Guilla... | Guillaume Caoursin |
| 4 | 331 | http://viaf.org/viaf/100208187 | Wikipedia@https://ru.wikipedia.org/wiki/Ришле,... | Ришле, Сезар-Пьер |
Check VIAF links by using the Bookdepository author names
All we need to do is to cross check and link the book depository authors to their VIAF pages (if it exists).
Note: The blow process takes a long time. Grab a coffee : )
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
links = []
author_with_viaf = []
books_with_viaf = []
names_to_predict = []
author_without_viaf = []
books_without_viaf = []
for i in range(len(books['authors'])):
# Find whether the name in bookdeposit dataset exists in VIAF dataset
name = books['authors'][i]
#print(i)
boolean_finding = viaf_db['Name'].str.contains(name, case=False).any() # True or False
# If its true get the viaf link
if boolean_finding == True:
df2 = viaf_db[(viaf_db['Name'].str.contains(name, case=False))]
viaf_link = df2['viaf'].loc[df2.index[0]]
links.append(viaf_link)
author_with_viaf.append(books['authors'][i])
books_with_viaf.append(books['titles'][i])
else:
names_to_predict.append(name)
author_without_viaf.append(books['authors'][i])
books_without_viaf.append(books['titles'][i])
print("Cross checking finished. If a VIAF link exists for an author it was saved in the list.")
1
2
3
4
5
6
7
8
9
10
11
12
13
# Convert lists to dataframe and then save locally (Saving the files makes it easier to test)
# Create dataframe from the lists
zipped1 = list(zip(author_with_viaf, books_with_viaf, links))
zipped2 = list(zip(author_without_viaf, books_without_viaf, names_to_predict))
viaf_authors = pd.DataFrame(zipped1, columns=['Author', 'Book', 'Links'])
predict_authors = pd.DataFrame(zipped2, columns=['Author', 'Book', 'Names'])
# storing these dataframes in a csv file
viaf_authors.to_csv(r'.../Viaf/Viaf-author-links-2021.csv') #, index = None
predict_authors.to_csv(r'.../Viaf/Author_names_to_predict-2021.csv')
1
2
3
4
5
b = len(books)
v = len(viaf_authors)
p = len(predict_authors)
print("There are {} books published in 2021 within Nature History category. This code managed to link {} of these book authors to their personal VIAF pages from which we will retrieve author gender information. We need to predict the gender for the remaining {} authors.".format(b,v,p))
There are 982 books published in 2021 within Nature History category. This code managed to link 311 of these book authors to their personal VIAF pages from which we will retrieve author gender information. We need to predict the gender for the remaining 671 authors.
Fetching gender data from VIAF pages with Beautifulsoup
1
2
3
4
5
6
7
8
9
10
# Import CSV
viaf_authors = pd.read_csv(".../Viaf/Viaf-author-links-2021.csv", dtype=str)
# Create an empty column for gender
viaf_authors["Gender"] = ""
# Drop unnecessary columns
viaf_authors.drop('Unnamed: 0', axis=1, inplace=True)
viaf_authors.head(5)
| Author | Book | Links | Gender | |
|---|---|---|---|---|
| 0 | Merlin Sheldrake | Entangled Life | http://viaf.org/viaf/31157340763509922488 | |
| 1 | Jeremy Clarkson | Diddly Squat | http://viaf.org/viaf/102195935 | |
| 2 | James Stewart | Dinosaur Therapy | http://viaf.org/viaf/121702213 | |
| 3 | James Rebanks | English Pastoral | http://viaf.org/viaf/311766886 | |
| 4 | Raynor Winn | The Wild Silence | http://viaf.org/viaf/74154921352863592450 |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
for i in range(len(viaf_authors)):
name = viaf_authors["Author"][i]
#print(i)
url = viaf_authors['Links'][i]
response = requests.get(url)
html = response.content
soup = BeautifulSoup(html, "lxml")
gender = []
for item in soup.select("div.subsection"):
text = item.text.strip()
text = text.replace('\n','')
text = text.replace('\t',' ')
text = text.replace(' ','')
gender.append(text)
text = text[0].split('Nationality')
text = str(text[0])
f = "Female" in gender[0]
m = "Male" in gender[0]
if f == True:
viaf_authors["Gender"][i] = "Female"
#print(name, "Female")
elif m == True:
viaf_authors["Gender"][i] = "Male"
#print(name, "Male")
else:
viaf_authors["Gender"][i] = "Unknown"
#print(name, "Unknown")
1
2
3
4
5
6
7
8
9
10
# Export to CSV
viaf_authors.to_csv('.../Viaf/Viaf-authors-gender-2021.csv')
# Import CSV
authors = pd.read_csv(".../Viaf/Viaf-authors-gender-2021.csv", dtype=str)
# Drop unnecessary columns
authors.drop('Unnamed: 0', axis=1, inplace=True)
authors.head(5)
| Author | Book | Links | Gender | |
|---|---|---|---|---|
| 0 | Merlin Sheldrake | Entangled Life | http://viaf.org/viaf/31157340763509922488 | NaN |
| 1 | Jeremy Clarkson | Diddly Squat | http://viaf.org/viaf/102195935 | NaN |
| 2 | James Stewart | Dinosaur Therapy | http://viaf.org/viaf/121702213 | NaN |
| 3 | James Rebanks | English Pastoral | http://viaf.org/viaf/311766886 | NaN |
| 4 | Raynor Winn | The Wild Silence | http://viaf.org/viaf/74154921352863592450 | NaN |
Statistics (VIAF)
1
2
3
4
5
6
7
8
9
10
f1 = authors['Gender'].value_counts()['Female'] # 113 <class 'numpy.int64'>
m1 = authors['Gender'].value_counts()['Male'] # 202
u1 = authors['Gender'].value_counts()['Unknown'] # 24
data1 = pd.DataFrame({
'female': [f1],
'male': [m1],
'unknown': [u1]
})
data1
| female | male | unknown | |
|---|---|---|---|
| 0 | 106 | 175 | 30 |
Predicting gender from first name by using Natural Language Processing
For those Book Depository author names that didn’t match with any VIAF data we can use NLTK to train and predict the binary gender of the authors from their first names.
Of course the method is problematic. Not just because it predicts and assigns the wrong gender to authors’ first name but also because of the binary gender assumption. In this method there is no room for non-binary and trans people. I tested the trained NLTK with my name and with 80% accuracy the code said I was a male. Well, I’m not.
1
2
3
4
5
# Source: https://www.geeksforgeeks.org/python-gender-identification-by-name-using-nltk/
import random
from nltk.corpus import names
import nltk
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Import CSV
predict_authors = pd.read_csv(".../Viaf/Author_names_to_predict-2021.csv", dtype=str)
# Create a colum for first names
predict_authors["FirstName"] = ""
predict_authors['FirstName'] = predict_authors['Names'].str.split(' ', expand=True)
# Create an empty column for gender
predict_authors["Gender"] = ""
# Drop unnecessary columns
predict_authors.drop('Unnamed: 0', axis=1, inplace=True)
predict_authors.head(5)
| Author | Book | Names | FirstName | Gender | |
|---|---|---|---|---|---|
| 0 | Lia Leendertz | The Almanac | Lia Leendertz | Lia | |
| 1 | Sosuke Natsukawa | The Cat Who Saved Books | Sosuke Natsukawa | Sosuke | |
| 2 | Lelia Wanick Salgado | Sebastiao Salgado. GENESIS | Lelia Wanick Salgado | Lelia | |
| 3 | Rodney Habib | The Forever Dog | Rodney Habib | Rodney | |
| 4 | Andrew Cotter | Dog Days | Andrew Cotter | Andrew |
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
import random
from nltk.corpus import names
import nltk
# Source1: ntlk prediction: https://www.geeksforgeeks.org/python-gender-identification-by-name-using-nltk/
def gender_features(word):
return {'last_letter':word[-1]}
# preparing a list of examples and corresponding class labels.
#labeled_names = ([(name, 'Female') for name in names.words('/Users/nat/Desktop/FemaleMix.rtf')]+
#[(name, 'Male') for name in names.words('/Users/nat/Desktop/MaleMix.rtf')]) # 133 f
labeled_names = ([(name, 'Female') for name in names.words('.../Names/female.txt')]+
[(name, 'Male') for name in names.words('.../Names/male.txt')])
random.shuffle(labeled_names)
# we use the feature extractor to process the names data.
featuresets = [(gender_features(n), gender)
for (n, gender)in labeled_names]
# Divide the resulting list of feature
# sets into a training set and a test set.
train_set, test_set = featuresets[500:], featuresets[:500]
# The training set is used to
# train a new "naive Bayes" classifier.
classifier = nltk.NaiveBayesClassifier.train(train_set)
predicted_gender = []
# Use the new dataframe with Nan instead of "book_database" dataframe because emoty cells cause issues.
for i in range(len(predict_authors)): #iterate over rows
# Get the name
name = predict_authors['FirstName'][i]
#print(name)
# If the name is in the database check gender
if name in open('.../Names/Allnames').read():
gender = classifier.classify(gender_features(name))
predict_authors["Gender"][i] = str(gender)
#print(gender)
# If the name is empty print unknown
elif name == 0:
predict_authors["Gender"][i] = "Unknown"
#print("Empty")
# If the name is not in the database print unknown
else:
#print ('Unknown')
predict_authors["Gender"][i] = "Unknown"
1
2
#pd.set_option('display.max_rows', None)
predict_authors.head(5)
| Author | Book | Names | FirstName | Gender | |
|---|---|---|---|---|---|
| 0 | Lia Leendertz | The Almanac | Lia Leendertz | Lia | Female |
| 1 | Sosuke Natsukawa | The Cat Who Saved Books | Sosuke Natsukawa | Sosuke | Unknown |
| 2 | Lelia Wanick Salgado | Sebastiao Salgado. GENESIS | Lelia Wanick Salgado | Lelia | Female |
| 3 | Rodney Habib | The Forever Dog | Rodney Habib | Rodney | Female |
| 4 | Andrew Cotter | Dog Days | Andrew Cotter | Andrew | Male |
Statistics (NTLK)
1
2
3
4
5
6
7
8
9
10
f2 = predict_authors['Gender'].value_counts()['Female'] # 133 OR 186
m2 = predict_authors['Gender'].value_counts()['Male'] # 296
u2 = predict_authors['Gender'].value_counts()['Unknown'] # 85
data2 = pd.DataFrame({
'female': [f2],
'male': [m2],
'unknown': [u2]
})
data2
| female | male | unknown | |
|---|---|---|---|
| 0 | 247 | 311 | 113 |
Summing it all up
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# Total of VIAF gender & predicted gender
total_f = f1 + f2
total_m = m1 + m2
total_u = u1 + u2
total_with_unknown = pd.DataFrame({
'Female': [total_f],
'Male': [total_m],
'Unknown': [total_u]
})
total_without_unknown = pd.DataFrame({
'Female': [total_f],
'Male': [total_m]
})
total_without_unknown
| Female | Male | |
|---|---|---|
| 0 | 353 | 486 |
Plots
Lets plot the results with and without the unknown gender.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
from matplotlib import pyplot as plt
mylabels = ["Female", "Male"]
mycolors = ["#34595a", "#a0c293"]
#controls default text size
plt.rc('font', size=15)
# plot size
plt.rcParams["figure.figsize"] = [10, 15]
#set title font to size 50
plt.rc('axes', titlesize=50)
plt.pie(total_without_unknown,
labels = mylabels,
autopct ='%1.1f%%',
colors = mycolors,
wedgeprops = {"edgecolor" : "black",
'linewidth': 2,
'antialiased': True})
#plt.legend(loc='upper left')
plt.title('Gender Gap')
# Save figure
plt.savefig('/Users/nat/Desktop/gender-gap.png', dpi = 100)
# Display the graph onto the screen
plt.show()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
fig = plt.figure()
mylabels1 = ["Female", "Male", "Unknown"]
mycolors1 = ["#34595a", "#a0c293", "#f0cfc3"]
mylabels2 = ["Female", "Male"]
mycolors2 = ["#34595a", "#a0c293"]
ax1 = fig.add_axes([0, 0, .5, .5], aspect=1)
ax1.pie(total_with_unknown,
labels=mylabels1,
radius = 1.2,
autopct ='%1.1f%%',
colors = mycolors1,
wedgeprops = {"edgecolor" : "black",
'linewidth': 2,
'antialiased': True})
ax2 = fig.add_axes([.5, .0, .5, .5], aspect=1)
ax2.pie(total_without_unknown,
labels=mylabels2,
radius = 1.2,
autopct ='%1.1f%%',
colors = mycolors2,
wedgeprops = {"edgecolor" : "black",
'linewidth': 2,
'antialiased': True})
ax1.set_title('Gender Gap')
#ax2.set_title('Title for ax2')
plt.show()
References
- Cima, R. (2017) The Gender Balance of The New York Times Best Seller List, The Pudding. Available at: https://pudding.cool/2017/06/best-sellers/index.html (Accessed: 1 March 2022).
- Holman, L., Stuart-Fox, D. and Hauser, C.E. (2018) ‘The gender gap in science: How long until women are equally represented?’, PLOS Biology. Edited by C. Sugimoto, 16(4), p. e2004956. doi:10.1371/journal.pbio.2004956.
- Reno, A. (2020) Author gender identity added to NoveList, EBSCO Information Services, Inc. Available at: https://www.ebsco.com/blogs/novelist/author-gender-identity-added-novelist (Accessed: 25 February 2022).